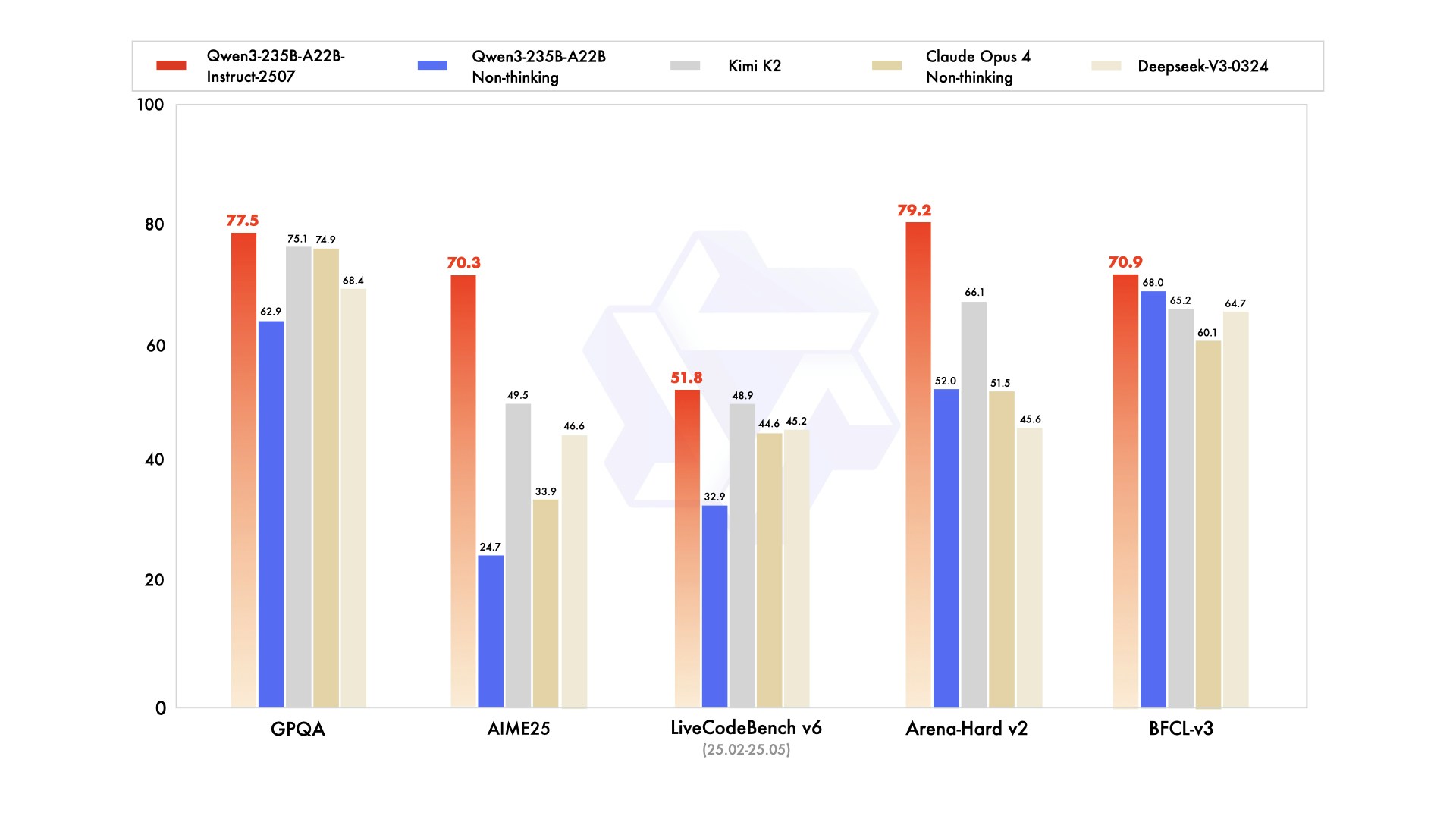
“After talking with the community and thinking it through, we decided to stop using hybrid thinking mode. Instead, we’ll train Instruct and Thinking models separately so we can get the best quality possible.”“A small update to Qwen3-235B-A22B, but a big improvement in quality!”
Qwen3-235B-A22B-2507 uses a Mixture of Experts (MoE) architecture with 235B total parameters — but only 22B are active at any given time! So you get massive model performance with much lower compute costs. Smart and efficient.
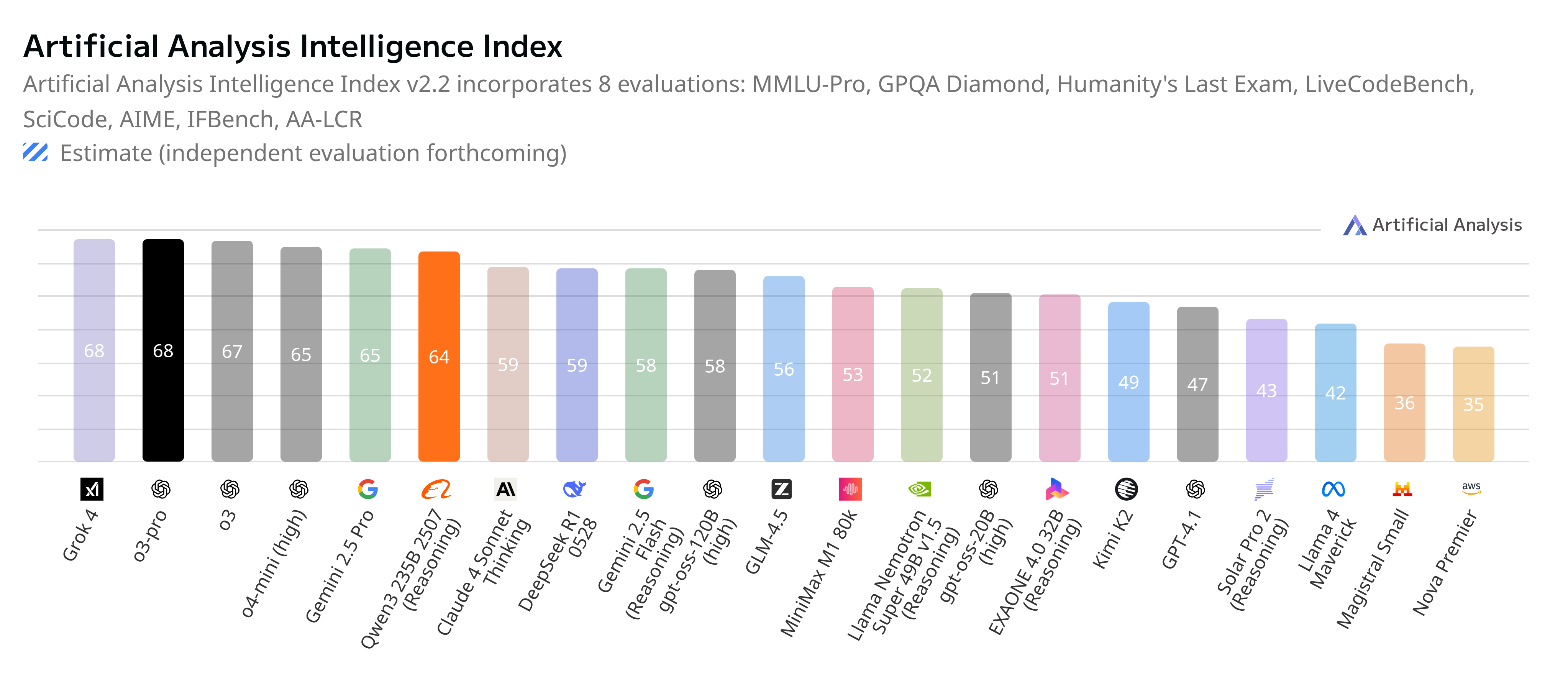
According to Artificial Analysis, Qwen3 is currently the top-performing open-source model — and it’s getting close to matching proprietary SOTA models.Source