- Generate high-quality training data via batched LLM generation using the recently released Qwen3-235B-A22B.
- Fine-tune a Qwen3-4B non-reasoning student model using LoRA adapters
- Deploy, evaluate and compare the distilled model with a 3.5x times larger model of this family, Qwen3-14B, using the most powerful open-source LLM to date, DeepSeek-R1, as evaluator.
Understanding Distillation
For more details on how distillation works see : Distillation explained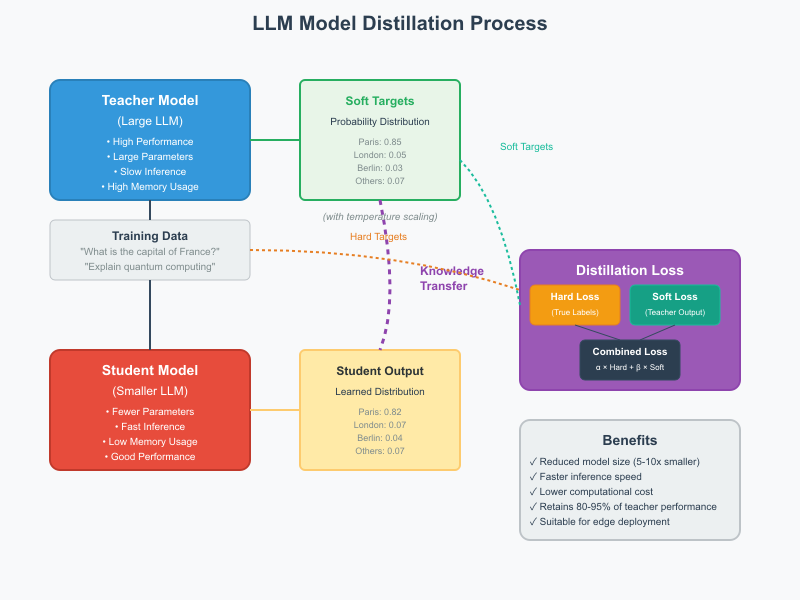
Setup
-
Get the code:
-
Install dependencies:
If using
uv(prefered):If usingpip: -
Create .env file in the project root and add your Nebius API key:
Running the code
If usinguv:
pip:
- open the notebook
- run with custom jupyter kernel we created in setup
Generate Synthetic Data
We are going to use a powerful LLMQwen3-235B-A22B to create some synthetic data from C4-200M dataset
We are going to run this using batch inference mode.
The runtime can take anywhere from 1 to 24 hours.
Note: we only have to do this once. Then we can use the generated output.
Run this notebook: 1_generate_synthetic_data_batch.ipynb
After successful completion we will see a file data/batch_output.jsonl .
Fine tuning
We use the data we generated in previous step to fine tune a ‘student model’ The fine tuned model will be saved intomodels directory.
Run this notebook: 2_fine_tuning.ipynb
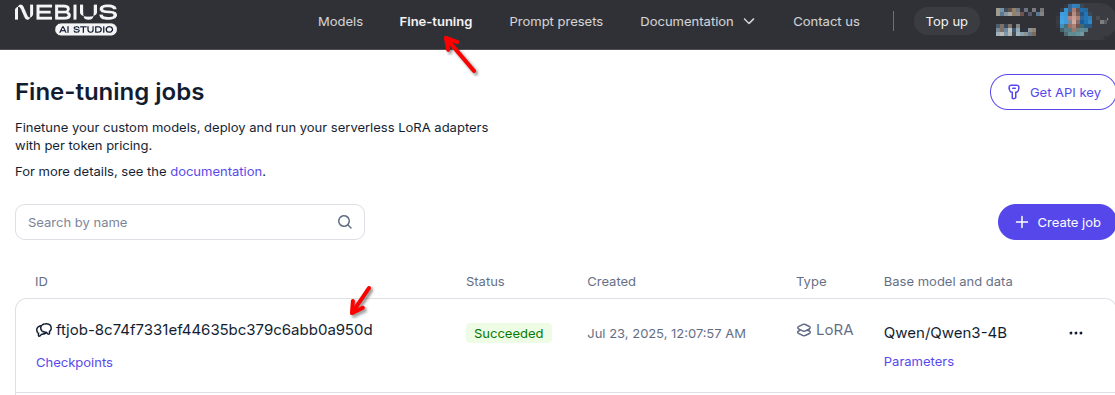
You can see fine tuning jobs’ status on the Studio fine-tuning dashboard
Verifing the distilled model
This notebook will show how to evaluate our distilled model (‘student’ model) We will use another powerful LLM DeepSeek-R1 as an evaluator Run notebook: 3_evaluate_model.ipynbYour distilled model in Nebius Studio
Find your distilled models in models —> custom section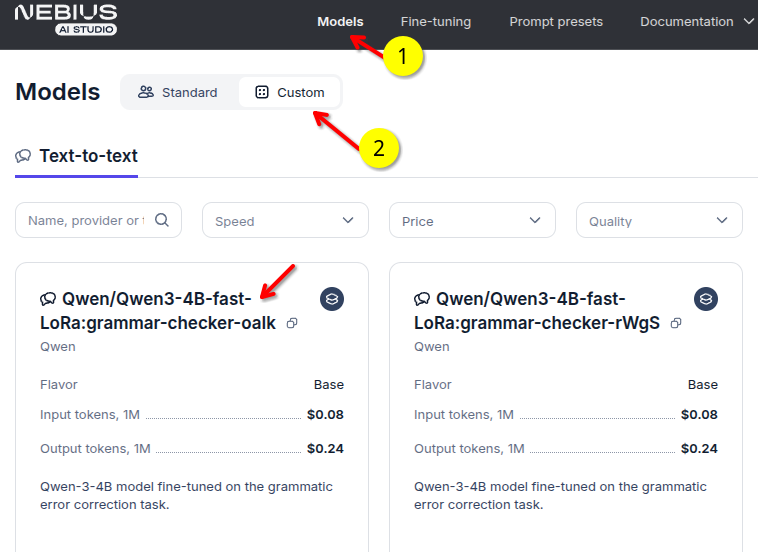
Using your distilled model
Try your new shiny model in the playground! Here you see the distilled model performing an grammer correction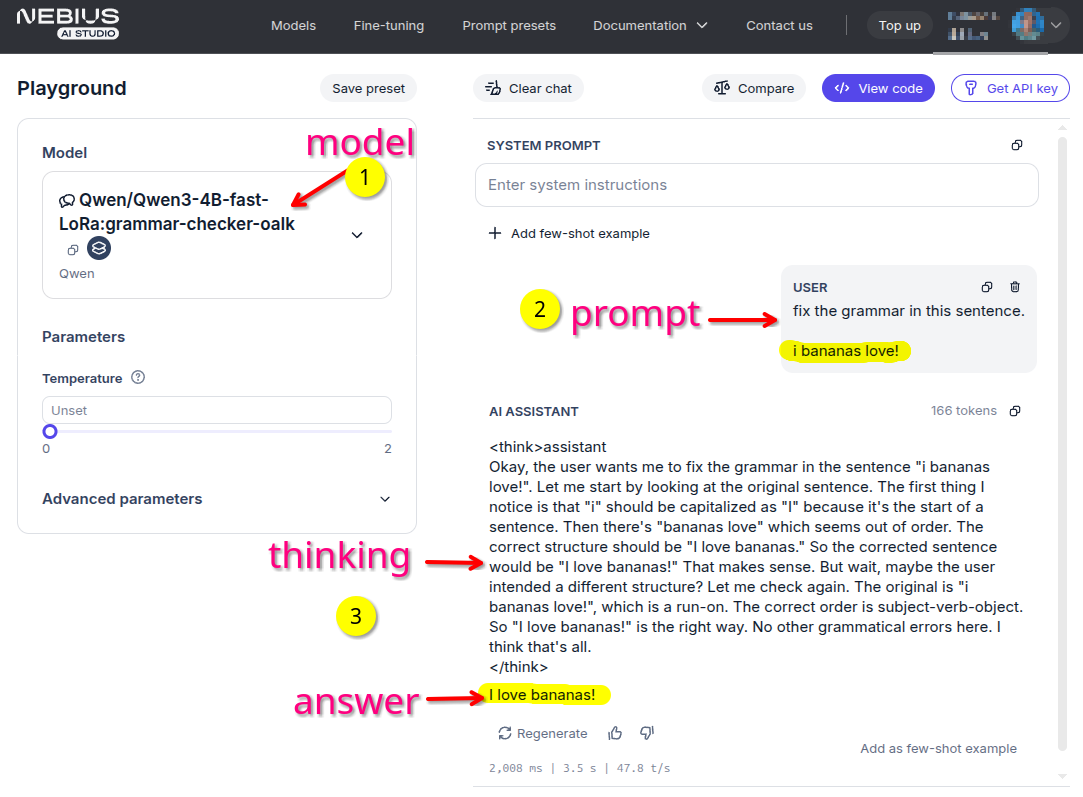
Use the distilled model using an API
See our API examples And documentationReferences
- Stahlberg, F., & Kumar, S. (2021). Synthetic data generation for grammatical error correction with tagged corruption models. In Proceedings of the 16th Workshop on Innovative Use of NLP for Building Educational Applications (pp. 37–47). Association for Computational Linguistics. https://www.aclweb.org/anthology/2021.bea-1.4
- Qwen Team. (2025, April 29). Qwen3: Think deeper, act faster. Qwen Blog. https://qwenlm.github.io/blog/qwen3/
- Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang and Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models. The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022, 2022. https://openreview.net/forum?id=nZeVKeeFYf9
- Napoles, C., Sakaguchi, K., & Tetreault, J. (2017). JFLEG: A fluency corpus and benchmark for grammatical error correction. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers (pp. 229–234). Association for Computational Linguistics. http://www.aclweb.org/anthology/E17-2037